

TLDR: Synthetic data is useful before market research, risky as market research, and dangerous when treated as a live read on a moving market. It should be combined with real world data, not used as a substitute.
A parent needs to buy school clothes for their child. The child lives in another city, so the parent brings the last photo they took, holds it against the racks, and reads the sizes from it.
For a few weeks, the clothes fit. But then the child grows—their sleeves ride up, shoes pinch, and the photo stops describing the child accurately. To shop again, the parent needs a new photo.
Synthetic data is similar to that photo: it captures a fixed data point (technically: a distribution, pattern, or statistical relationship) and lets you act on it for a while.
But the picture decays as the subject keeps moving, and the only fix is another snapshot.

What is synthetic data?
The 2025 ICC/ESOMAR Code defines synthetic data as information generated to replicate the characteristics of real-world data.
In technical terms, synthetic data is computer-generated data built to copy the statistical properties and patterns of original data without using the records themselves.
A synthetic dataset extends an existing one to answer new questions.
A synthetic persona stands in for a target segment.
A synthetic respondent answers a full survey as a defined character.
Critics often dismiss the output as fake data, but the underlying limitation deserves a closer look.
How synthetic data gets made
Data scientists produce synthetic data in three main ways.
- A rules engine writes artificial data from set instructions, which suits mock data or test data for software teams.
- A statistical method copies the mean, variance, and other statistical properties of an existing dataset, then an algorithm samples fresh data points.
- A generative model, often a generative adversarial network or a large language model, learns the distribution of the original dataset and produces new records that follow the same patterns.
Generative AI, a branch of artificial intelligence, now drives most of the attention, because that one approach can output tabular data, text, and synthetic images.
The practice predates today’s generative AI. It grew up alongside big data and software testing, driven by two older problems:
- ML models needed large training data and rarely had enough, so a data scientist would generate more to fill the set.
- Privacy teams needed to share information without exposing sensitive data, so they’d replace a real world dataset with a synthetic one.
That second use overlaps with data masking, which swaps personal details with fabricated values inside a real dataset; and data augmentation, which transforms copies of existing data to enlarge a set.
Synthetic data goes further, building new data rather than just disguising or duplicating actual data.
How far has synthetic data generation come?
Synthetic datasets have come a long way fast. Generative AI now produces synthetic respondents that answer survey questions in seconds.
Companies like Synthetic Users and Qualtrics sell synthetic datasets on demand. Synthetic Users charges $2 to $60 per interview depending on complexity, Artificial Societies used to run a self-serve tier as low as $40 a month.
Articos charges $47/mo, and platforms like Ditto scale toward enterprise tiers, with pilots from $5,000 and annual platform access from $35,000 a year.
Gartner predicted 75% of businesses will use generative AI to create synthetic customer data by 2026. Analysts project the sector to grow at a 31.1% CAGR through 2034.
Regulated sectors like healthcare and banking are betting hard on synthetic data generation to solve complex challenges each face.
Philips, a key partner in Project SEARCH, builds synthetic datasets around CT and MRI scans. They do this to train diagnostic AI for oncology and cardiovascular care without exposing real patient data.
Separately, JP Morgan’s AI Research division runs an active synthetic data programme covering fraud detection, anti-money-laundering models, and customer behaviour, without touching production data.
Vendors report that synthetic panels reduce sample costs by up to 50% against traditional procurement, and they reach audiences that agencies struggle to field, such as senior executives and regulated buyers.
That makes it a fast tool for screening ideas, pre-testing survey wording, and narrowing a concept list before any human sees it.
Where a synthetic dataset gets stale
Synthetic data may not stand in accurately for current opinion. ML models learn from training data gathered in the past, and generate new answers by reproducing the patterns inside that training data.
So it describes the market as it was, not as it is. The photo holds for a season, then drifts. This persists unless it’s refreshed with recent data, connected to live sources, or recalibrated.
A Columbia-led mega-study, released as a 2026 arXiv preprint, tested digital twins built from more than 500 prior answers per person.
The answers covered demographics, personality, cognitive ability, economic preferences, behavioural experiments, and pricing responses.
Across 19 pre-registered studies and 164 outcomes, full-persona twins reached 0.748 individual-level accuracy, compared with 0.734 for an empty-persona prompt.
In other words, adding the person’s long prior response history improved accuracy by only 1.4 percentage points.
The twins were also under-dispersed relative to human answers in 93.9% of outcomes, meaning their answers clustered too tightly and missed much of the spread found in human responses.
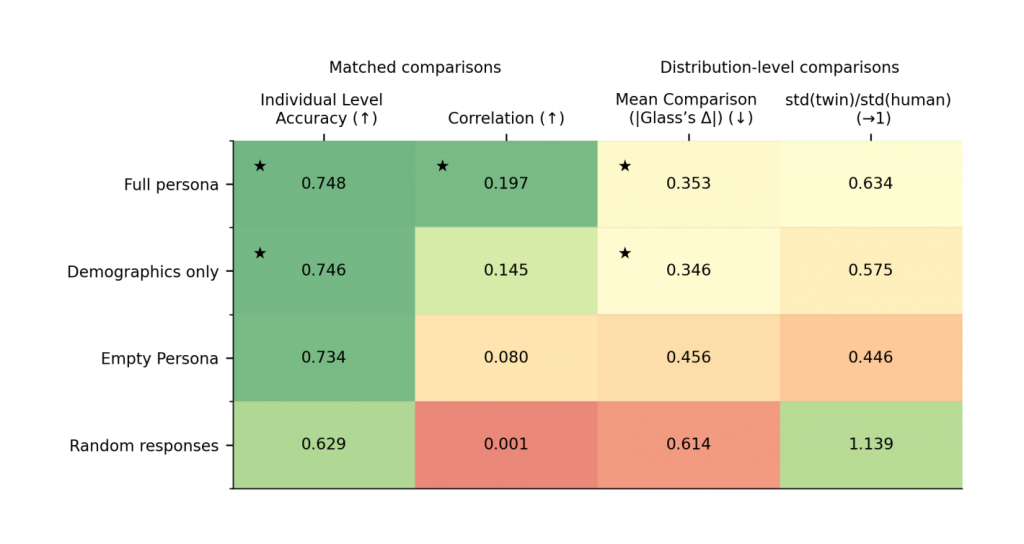
That clustering presents a homogeneity risk. A model that synthesizes what a 24-year-old buyer might say leans on the average of its training data and can flatten the differences between one 24-year-old and another across income, region, and culture.
The same study found a counter-signal, though: richer personas captured relative differences between people better than demographics did, even if it remains a modest correlation.
From the paper: “In sum, enriching digital twins with detailed individual-level information significantly improves individual-level prediction, that is, the ability to reproduce the exact responses given by specific participants. However, the improvement over an empty persona is negligible. Second, digital twins significantly improve our ability to capture heterogeneity across participants and predict relative differences between them, that is, it enhances our ability to distinguish one participant from another. However, the correlation between answers from digital twins and their human counterparts is modest.”
A weak synthetic dataset can create a false sense of uniformity, flattening the messy variation that exists across income, region, culture, and timing.
Gartner predicts that by 2027, 60% of data and analytics leaders will face critical failures from poorly managed synthetic data, including damage to model accuracy and compliance.
A model trained on an incomplete dataset also amplifies the bias it inherits, reproducing them confidently.
The output reads as realistic data, making a stale answer hard to spot.
| Where synthetic data holds up | Where synthetic data fails |
| Screening early concepts and ideas | Producing population estimates with defensible confidence |
| Pre-testing survey wording and flow | Predicting unseen behaviour with no past analog |
| Boosting small, hard-to-reach segments | Reading fast-moving or emerging audiences |
| Refining a question before fielding it | Final go/no-go decisions on capital or reputation |
Using synthetic data set without being misled
None of this makes synthetic data useless, but it narrows the use case somewhat. A synthetic record works as a supplement rather than a substitute for real world data.
The mature path is to take a hybrid approach: real data + artificial datasets generated by AI models.
Data science teams can use synthetic respondents for fast iteration early in a project, then commit to human respondents and realistic datasets for more consequential decisions.
Companies that keep talking to their customer base—through always-on panels, regular interviews, and live feedback loops—hold a current picture.
They can then use synthetic data to refine the questions they bring to those conversations, not to answer them.